9. Database Structure (GDS file)
GDS is a proprietary internal database structure used to store global variables and lock resource names. A high-level understanding of GDS can help database administrators correctly interpret YottaDB logs/error messages, and maintain database metrics. You should always consult YottaDB support (info@yottadb.com) in the unlikely event of getting database integrity issues.
Note
This chapter provides a high-level overview of GDS components. A comprehensive description of all the components of GDS is beyond the scope of this chapter.
Database File Organization with GDS
YottaDB processes a GDS file using predominantly low-level system services. The GDS file consists of two parts:
The database file header
The database itself
Database File Header
The fields in the file header convey the following types of information:
Data Elements
Master Bitmap
File Header Data Elements
All YottaDB components, except GDE, (the run-time system, DSE, LKE, MUPIP) use the data elements of the file header for accounting, control, and logging purposes.
The current state of the file header always determines the characteristics of the database. The MUPIP CREATE command initializes the values of the file header data elements from the global directory and creates a new .DAT file.
The file header data elements are listed as follows in alphabetical order for easier access, rather than the order in which they appear in the file header.
Data Elements |
Description |
|---|---|
Access method |
The buffering strategy of the database. Access Method can have 2 values - BG or MM. The default value is BG. Buffered Global (BG) manages the buffers (the OS/file system may also buffer "in series"); MM - the OS/file system manages all the buffering. |
Async IO |
Whether the database file uses Asynchronous or Synchronous I/O. For additional information, see Global Directory Editor (GDE). |
Block size (in bytes) |
The size (in bytes) of a GDS block. Block size can have values that are multiples of 512. The default value is 4096. Block size should be a multiple of the native block size for the OS file system chosen to accommodate all but outlying large records. For additional information, see Global Directory Editor (GDE). |
Blocks to Upgrade |
This field should be ignored in r2.00. |
Cache freeze id |
The process identification number (PID) of a process which has suspended updates to the segment. |
Certified for Upgrade to |
This field is V6, V7m, or V7. V6 is the YottaDB r1.x database format, and V7 is the YottaDB r2.x database format. V7m indicates a V6 database file in an intermediate state: UPGRADE has been run, but [-]-UPGRADE has not yet been fully run. |
Create in progress |
Create in progress is TRUE only during the MUPIP CREATE operation. The normal value is FALSE. |
Collation Version |
The version of the collation sequence definition assigned to this database. DSE only reports this if an external collation algorithm is specified. |
Commit Wait Spin Count |
COMMITWAIT_SPIN_COUNT specifies the number of times a YottaDB process waiting for control of a block to complete an update should spin before yielding the CPU when YottaDB runs on SMP machines. |
Current transaction |
The 64-bit hexadecimal number of the most recent database transaction. |
Data Reserved Bytes |
Number of bytes reserved (not used by YottaDB) in data-level database blocks. |
DB is auto-created |
Indicates whether the database file is automatically created. |
DB shares gvstats |
Indicates whether the database supports sharing of statistics. |
Default Collation |
The collation sequence currently defined for this database. DSE only reports this if an external collation algorithm is defined. |
Desired DB Format |
The desired version format of database blocks. Desired DB Format can have 2 possible values- the major version for the current running YottaDB distribution or the last prior major version. Newly created databases and converted databases have the current major version. |
Endian Format |
The Endian byte ordering of the platform. This is always LITTLE for YottaDB. |
Extension Count |
The number of GDS blocks by which the database file extends when it becomes full. The default value is 100 and the maximum is 65535. In production, typically this value should reflect the amount of new space needed in a relatively long period (say a week or a month). Linux file systems use lazy allocations so this value controls the frequency at which YottaDB checks the actual available space for database expansion in order to warn when space is low. |
Flush timer |
Indicates the time between completion of a database update and initiation of a timed flush of modified buffers. The default value is 1 second and the maximum value is 1 hour. |
Flush trigger |
The total number of modified buffers that trigger an updating process to initiate a flush. The maximum and default value is 93.75% of the global buffers; the minimum is 25% of the global buffers. |
Free blocks |
The number of GDS blocks in the data portion of the file that are not currently part of the indexed database (that is, not in use). MUPIP INTEG NOONLINE (including -FAST) can rectify this value if it is incorrect. |
Free space |
The number of currently unused blocks in the fileheader (for use by enhancements). |
Global Buffers |
The number of BG buffers for the region. The minimum value is 64 and the maximum is 2147483647. The default value is 1024. In a production system, this value should typically be higher. |
In critical section |
The process identification number (PID) of the process in the write-critical section, or zero if no process holds the critical section. |
Index Reserved Bytes |
Number of bytes reserved (not used by YottaDB) in index-level database blocks. |
Journal Alignsize |
Specifies the number of 512-byte-blocks in the alignsize of the journal file. DSE only reports this field if journaling is ENABLED (or ON). If the ALIGNSIZE is not a perfect power of 2, YottaDB rounds it up to the nearest power of 2. The default and minimum value is 4096. The maximum value is 4194304 (=2 GigaBytes). A small alignsize can make for faster recover or rollback operations, but makes less efficient use of space in the journal file. |
Journal Allocation |
The number of blocks at which YottaDB starts testing the disk space remaining to support journal file extensions. DSE only reports this field if journaling is ENABLED or ON. |
Journal AutoSwitchLimit |
The number of blocks after which YottaDB automatically performs an implicit online switch to a new journal file. DSE only reports this field if journaling is ENABLED or ON. The default value for Journal AutoSwitchLimit is 8386560 & the maximum value is 8388607 blocks (4GB-512 bytes). The minimum value is 16384. If the difference between the Journal AutoSwitchLimit and the allocation value is not a multiple of the extension value, YottaDB rounds-down the value to make it a multiple of the extension value and displays an informational message. |
Journal Before imaging |
Indicates whether or not before image journaling is allowed; DSE only reports this field if journaling is ENABLED or ON. Journal Before imaging can either be TRUE or FALSE. |
Journal Buffer Size |
The amount of memory allotted to buffer journal file updates. The default value is 2312. The minimum is 2307 and the maximum is 1Mi blocks which means that the maximum buffer you can set for your journal file output is 512MB. Larger journal buffers can improve run-time performance, but they also increase the amount of information at risk in failure. Journal Buffer size must be large enough to hold the largest transaction. |
Journal Epoch Interval |
The elapsed time interval between two successive EPOCHs in seconds. An EPOCH is a checkpoint, at which all updates to a database file are committed to disk. All journal files contain epoch records. DSE only reports this field if journaling is ENABLED or ON. The default value is 300 seconds (5 minutes). The minimum is 1 second and the maximum value is 32,767 (one less than 32K) seconds, or approximately 9.1 hours. Longer Epoch Intervals can increase run-time performance, but they can also cause longer recovery times. |
Journal Extension |
The number of blocks used by YottaDB to determine whether sufficient space remains to support continuing journal file growth. DSE only reports this field if journaling is ENABLED or ON. The default value is 2048 blocks. The minimum is zero (0) blocks and the maximum is 1073741823 (one less than 1 giga) blocks. In production, this value should typically be either zero (0) to disable journal extensions and rely entirely on the Journal Allocation, or it should be large. In UNIX, this value serves largely to allow you to monitor the rate of journal file growth. UNIX file systems use lazy allocation so this value controls the frequency at which YottaDB checks the actual available space for journal file expansion in order to warn when space is low. |
Journal File |
The name of the journal file. DSE only reports this field if journaling is ENABLED or ON. |
Journal State |
Indicates whether journaling is ON, OFF, or DISABLED (not allowed). If it reports that journaling is ON, you may also see [inactive] next to it. This means that journaling is ON, but no process has opened the journal file yet in shared memory. For example, if processes just do reads of globals then the journal file is not opened even though the database file is opened. |
Journal Sync IO |
Indicates whether WRITE operation to a journal file commits directly to disk. The default value is FALSE. DSE only reports this field if journaling is ENABLED (or ON). |
Journal Yield Limit |
The number of times a process needing to flush journal buffer contents to disk yields its timeslice and waits for additional journal buffer content to be filled-in by concurrently active processes, before initiating a less than optimal I/O operation. The minimum Journal Yield Limit is 0, the maximum Journal Yield Limit is 2048. The default value for Journal Yield Limit is 8. On a lightly loaded system, a small value can improve run-time performance, but on actively updating systems a higher level typically provides the best performance. |
KILLs in progress |
The sum of the number of processes currently cleaning up after multi-block KILLs and the number of Abandoned KILLs. Abandoned KILLs are associated with block-incorrectly-marked-busy errors. |
Last Bytestream Backup |
The transaction number of the last transaction backed up with the MUPIP BACKUP -BYTESTREAM command. |
Last Database Backup |
The transaction number of the last transaction backed up with the MUPIP BACKUP -DATABASE command. (Note -DATABASE is the default BACKUP type.) |
Last Record Backup |
Transaction number of last MUPIP BACKUP -RECORD or FREEZE -RECORD command. |
LOCK shares DB critical section |
Whether LOCK activity shares the resource manager for the database or has a separate and different critical section manager. |
Lock space |
A hexadecimal number indicating the 512 byte pages of space dedicated to LOCK information. The minimum Lock space is 10 pages and the maximum is 65,536 pages. The default is 40 pages. In production with an application that makes heavy use of LOCKS, this value should be higher. |
Master Bitmap Size |
The size of the Master Bitmap. The current Master Bitmap Size of the database is 496 (512 byte blocks). |
Maximum key size |
The minimum key size is 3 bytes and the maximum key size is 1019 bytes. For information on setting the maximum key size for your application design, refer to Global Directory Editor (GDE). |
Maximum record size |
The minimum record size is zero. A record size of zero only allows a global variable node that does not have a value. The maximum is 1,048,576 bytes (1MiB). The default value is 256 bytes. An error occurs if you decrease and then make an attempt to update nodes with existing longer records. |
Maximum TN |
The maximum number of TNs that the current database can hold. For a database in the most recent format, the default value of Maximum TN is 18,446,744,039,416,922,111 or 0xFFFFFFF803FFFFFF. |
Maximum TN Warn |
The transaction number after which YottaDB generates a warning and update it to a new value. The default value of Maximum TN Warn is 0xFFFFFFD813FFFFFF. |
Modified cache blocks |
The current number of modified blocks in the buffer pool waiting to be written to the database. |
Mutex Hard Spin Count |
The number of attempts to grab the mutex lock before initiating a less CPU-intensive wait period. The default value is 128. |
Mutex Sleep Spin Count |
The number of timed attempts to grab the mutex lock before initiating a wait based on interprocess wake-up signals. The default value is 128. |
Mutex Spin Sleep Time |
The number of milliseconds to sleep during a mutex sleep attempt. The default value is 2048. |
No. of writes/flush |
The number of blocks to write in each flush. The default value is 7. |
Null subscripts |
"ALWAYS" if null subscripts are legal. "NEVER" if they are not legal and "EXISTING" if they can be accessed and updated, but not created anew. |
Number of local maps |
(Total blocks + 511)512. |
Online Backup NBB |
Block to which online backup has progressed. DSE displays this only when an online backup is currently in progress. |
Reference count |
The number of YottaDB processes and utilities currently accessing that segment on a given node. Note: YottaDB does not rely on this field. A database segment initially has a reference count of zero. When a YottaDB process or utility accesses a segment, YottaDB increments the reference count. YottaDB decrements the reference count upon termination. YottaDB counts DSE as a process. When examining this field with DSE, the reference count is always greater than zero. When DSE is the only process using a region, the reference count should be one. |
Region Seqno |
The current replication relative time stamp for a region. |
Replication State |
Either On or OFF. [WAS_ON] OFF means that replication is still working, but a problem with journaling has caused YottaDB to turn it off, so YottaDB is still replicating, but will turn replication OFF if it ever has to turn to the journal because the pool has lost data needed for replication. |
Reserved Bytes |
Number of bytes reserved in database blocks. |
Starting VBN |
Virtual Block Number of the first GDS block after the GDS file header; this is block 0 of the database and always holds the first local bitmap. |
Timers pending |
Number of processes considering a timed flush. |
Total blocks |
Total number of GDS blocks, including local bitmaps. |
WIP queue cache blocks |
The number of blocks for which YottaDB has issued writes that have not yet complete. |
Wait Disk |
Seconds that YottaDB waits for disk space to become available before it ceases trying to flush a GDS block's content to disk. During the wait, it sends eight (8) approximately evenly spaced operator log messages before finally issuing a YDB-E-WAITDSKSPACE error. For example, if Wait Disk is 80 seconds and YottaDB finds no disk space to flush a GDS block, it sends a YDB-E-WAITDSKSPACE syslog message about every 10 seconds, and after the eighth message issues a WAITDSKSPACE error. This field is only used in UNIX because of its reliance on lazy disk space allocation. |
Zqgblmod Seqno |
The replication sequence number associated with the $Zqgblmod() Transaction number. |
Zqgblmod Trans |
Transaction number used by the $ZQGBLMOD() function in testing whether a block was modified by overlapping transactions during a replication switchover. |
Average Blocks Read per 100 Records |
Acts as a clue for replication update helper processes as to how aggressively they should attempt to prefetch blocks. It's an estimate of the number of database blocks that YottaDB reads for every 100 update records. The default value is 200. For very large databases, you can increase the value up to 400 |
Update Process Reserved Area |
An approximate percentage (integer value 0 to 100) of the number of global buffers reserved for the update process. The reader helper processes leaves at least this percentage of the global buffers for the update process. It can have any integer value between 0 to 100. The default value is 50. |
Pre read trigger factor |
The percentage of Update Process reserved area, after which the update process processes signal the reader helper processes to resume processing journal records and reading global variables into the global buffer cache. It can have any integer value between 0 to 100. The default value is 50. |
Update writer trigger factor |
One of the parameters used by YottaDB to manage the database is the flush trigger. One of several conditions that triggers normal YottaDB processes to initiate flushing dirty buffers from the database global buffer cache is when the number of dirty buffers crosses the flush trigger. In an attempt to never require the update process itself to flush dirty buffers, when the number of dirty global buffers crosses the update writer trigger factor percentage of the flush trigger value, writer helper processes start flushing dirty buffers to disk. It can have any integer value between 0 to 100. The default value is 33, that is, 33%. |
Local Bitmaps
YottaDB partitions GDS blocks into 512-block groups. The first block of each group contains a local bitmap. A local bitmap reports whether each of the 512 blocks is currently busy or free and whether it ever contained valid data that has since been KILLed.
The two bits for each block have the following meanings:
00 - Busy
01 - Free and never used before
10 - Currently not a legal combination
11 - Free but previously used
These two bits are internally represented as:
'X' - BUSY
'.' - FREE
'?' - CORRUPT
':' - REUSABLE
The interpreted form of the local bitmap is like the following:
Block 0 Size 90 Level -1 TN 1 V7 Master Status: Free Space
Low order High order
Block 0: | XXXXX... ........ ........ ........ |
Block 20: | ........ ........ ........ ........ |
Block 40: | ........ ........ ........ ........ |
Block 60: | ........ ........ ........ ........ |
Block 80: | ........ ........ ........ ........ |
Block A0: | ........ ........ ........ ........ |
Block C0: | ........ ........ ........ ........ |
Block E0: | ........ ........ ........ ........ |
Block 100: | ........ ........ ........ ........ |
Block 120: | ........ ........ ........ ........ |
Block 140: | ........ ........ ........ ........ |
Block 160: | ........ ........ ........ ........ |
Block 180: | ........ ........ ........ ........ |
Block 1A0: | ........ ........ ........ ........ |
Block 1C0: | ........ ........ ........ ........ |
Block 1E0: | ........ ........ ........ ........ |
'X' == BUSY '.' == FREE ':' == REUSABLE '?' == CORRUPT
Note
The first block described by the bitmap is itself and is therefore always marked busy.
If bitmaps are marked as "?", they denote that they are corrupted (not currently in a legal combination) bitmaps. The consequences of corrupted bitmaps are:
Possible loss of data when YottaDB overwrites a block that is incorrectly marked as free (malignant).
Reduction in the effective size of the database by the number of blocks incorrectly marked as busy (benign).
Master Bitmap
Using bitmaps, YottaDB efficiently locates free space in the database. A master bitmap has one bit per local bitmap which indicates whether the corresponding local bitmap is full or has free space. When there is no free space in a group of 512 blocks, YottaDB clears the associated bit in the master map to show whether the local bitmap is completely busy. Otherwise, YottaDB maintains the bit set.
There is only one Master Bitmap per database. You can neither see the contents of the master bitmap directly nor change the size of the master bitmap. The maximum size of a single YottaDB database file is 992 Mi blocks. A logical database consists of an arbitrarily large number of database files.
The size of the master bitmap constrains the size of the database. The size of the master map reflects current expectations for the maximum operational size of a single database file.
Note
In addition to the limit imposed by the size of the master map, YottaDB currently limits a tree to a maximum number of 7 levels. This means that if a database holds only one global, depending on the density and size of the data, it might reach the level limit before the master map limit.
Database Structure
The YottaDB database structure is hierarchical, based on a form of balanced tree called a B-star tree (B*-tree) structure. The B*-tree contains blocks that are either index or data blocks. An index block contains pointers used to locate data in data blocks, while the data blocks actually store the data. Each block contains a header and records. Each record contains a key and data.
Tree Organization
GDS structures data into multiple B*-trees. YottaDB creates a new B*-tree, called a Global Variable Tree (GVT), each time the application defines a new named global variable. Each GVT stores the data for one named global, i.e., all global variables (gvn) that share the same unsubscripted global name. For example, global ^A, ^A(1), ^A(2), ^A("A"), and ^A("B") are stored in the same GVT. Note that each of these globals share the same unsubscripted global name, that is, ^A. A GVT contains both index and data blocks and can span several levels. The data blocks contain actual global variable values, while the index blocks point to the next level of block.
At the root of the B*-tree structure is a special GDS tree called a Directory Tree (DT). DT contains pointers to the GVT. A data block in the DT contains an unsubscripted global variable name and a pointer to the root block of that global variable's GVT.
All GDS blocks in the trees have level numbers. Level zero (0) identifies the terminal nodes (that is, data blocks). Levels greater than zero (0) identify non-terminal nodes (that is, index blocks). The highest level of each tree identifies the root. All the B*-trees have the same structure. Block one (1) of the database always holds the root block of the Directory Tree.
The following illustration describes the internal GDS B*-tree framework YottaDB uses to store globals.
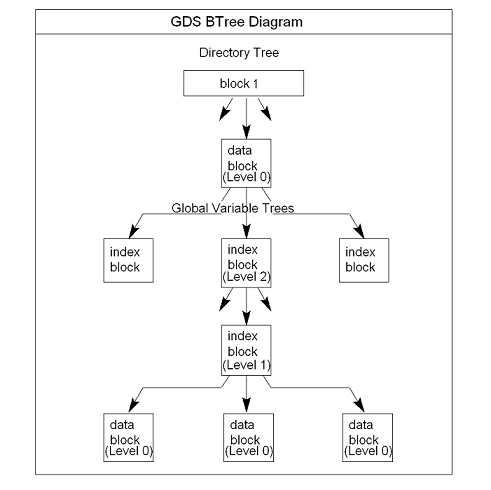
YottaDB creates a new GVT when a SET results in the first use of an unsubscripted global name by referring to a subscripted or unsubscripted global variable with a name prefix that has not previously appeared in the database.
Note
GVTs continue to exist even after all nodes associated with their unsubscripted name are KILLed. An empty GVT occupies negligible space and does not affect YottaDB performance. However, if you are facing performance issues because you have many empty GVTs, you need to reorganize your database file using MUPIP EXTRACT, followed by MUPIP CREATE, and the MUPIP LOAD to remove those empty GVTs.
The following sections describe the details of the database structures.
GDS Blocks
Index and data blocks consist of a block header followed by a series of records. The block header has five fields. The first field, of two bytes, specifies the block version. The second field, of one byte, is a filler byte. The third field, of one byte, specifies the block level. The fourth field, of two bytes, specifies the number of bytes currently in use in the block. The last field of eight bytes represents the transaction number at which the block was last changed. An interpreted form of a block header looks like the following:
File /home/jdoe/.yottadb/r1.20_x86_64/g/yottadb.dat
Region DEFAULT
Block 3 Size 262 Level 0 TN 3845EE V6
Depending on the platform, there may also be an empty field containing filler to produce proper alignment. The filler occurs between the second and third data field and causes the length of the header to increase from seven to eight bytes.
GDS Records
Records consist of a record header, a key, and either a block pointer or the actual value of a global variable name (gvn). Records are also referred to as nodes.
The record header has two fields that contain information. The first field, of two bytes, specifies the record size. The second field, of one byte, specifies the compression count.
Note
Like the GDS block headers, a filler byte may be added in the third field, depending on the platform. For example, "61" in the following example is added as a filler byte.
The interpreted form of a block with global ^A("Name",1)="Brad" looks like the following:
Rec:1 Blk 3 Off 10 Size 14 Cmpc 0 Key ^A("Name",1)
10 : | 14 0 0 61 41 0 FF 4E 61 6D 65 0 BF 11 0 0 42 72 61 64|
| . . . a A . . N a m e . . . . . B r a d|
The data portion of a record in any index block consists of a four-byte block pointer. Level 0 data in the Directory Tree also consists of four-byte block pointers. Level 0 data in Global Variable Trees consists of the actual values for global variable names.
Using GDS records to hold spanning nodes
A global variable node spans across multiple blocks if the size of its value exceeds one database block. Such a global variable node is called a "spanning node". For example, if ^a holds a value that exceeds one database block, YottaDB internally spans the value of ^a in records with keys ^a(#SPAN1), ^a(#SPAN2), ^a(#SPAN3), ^a(#SPAN4), and so on. Note that #SPAN1, #SPAN2, #SPAN3, #SPAN4, and so on are special subscripts that are visible to the database but invisible at the M application level. YottaDB uses these special subscripts to determine the sequence of the spanning nodes.
The first special subscript #SPAN1 is called a "special index". A special index contains the details about the size of the spanning node's value and the number of additional records that are necessary to hold its value. #SPAN2 and the rest of the records hold chunks of the value of the spanning node. During the load of a binary extract, YottaDB uses these chunks to reconstitute the value of a global. This allows globals to be re-spanned if the block size of the source database is different from the block size of the destination database.
Note
If the destination database's block size is large enough to hold the key and value, then the global is not a spanning node (because it can fit in one database block).
GDS Keys
A key is an internal representation of a global variable name. A byte-by-byte comparison of two keys conforms to the collating sequence defined for global variable nodes. The default collating sequence is the one specified by the M standard. For more information on defining collating sequences, see the "Internationalization" chapter in the Programmer's Guide.
Compression Count
The compression count specifies the number of bytes at the beginning of a key that are common to the previous key in the same block. The first key in each block has a compression count of zero. In a global variable tree, only the first record in a block can legitimately have a compression count of zero.
Record Key |
Compression Count |
Resulting Key in Record |
|---|---|---|
CUS(Jones,Tom) |
0 |
CUS(Jones,Tom) |
CUS(Jones,Vic) |
10 |
Vic) |
CUS(Jones,Sally) |
10 |
Sally) |
CUS(Smith,John) |
4 |
Smith,John) |
The previous table shows keys in M representation. For descriptions of the internal representations, refer to the section on keys.
The non-compressed part of the record key immediately follows the record header. The data portion of the record follows the key and is separated from the key by two null (ASCII 0) bytes.
Use of Keys
YottaDB locates records by finding the first key in a block lexically greater than or equal to the current key. If the block has a level of zero (0), the location is either that of the record in question or if the record in question does not exist, that of the (lexically) next record. If the block has a level greater than zero (0), the record contains a pointer to the next level to search.
YottaDB does not require that the key in an index block correspond to an actual existing key at the next level.
The final record in each index block (the *-record) contains a *-key ("star-key"). The *-key is a zero-length key representing the last possible value of the M collating sequence. The *-key is the smallest possible record, consisting only of a record header and a block pointer, with a key size of zero (0).
The *-key has the following characteristics:
A record size of seven (7) or eight (8) bytes (depending on endian)
A record header size of three (3) or four (4) bytes (depending on endian)
A key size of zero (0) bytes
A block pointer size of four (4) bytes
Characteristics of Keys
Keys include a name portion and zero or more subscripts. YottaDB formats subscripts differently for string and numeric values.
Keys in the Directory Tree represent unsubscripted global variable names. Unlike Global Variable Tree keys, Directory Tree keys never include subscripts.
Single null (ASCII 0) bytes separate the variable name and each of the subscripts. Two contiguous null bytes terminate keys. YottaDB encodes string subscripts and numeric subscripts differently.
During a block split the system may generate index keys which include subscripts that are numeric in form but do not correspond to legal numeric values. These keys serve in index processing because they fall in an appropriate place in the collating sequence. When DSE represents these "illegal" numbers, it may display many zero digits for the subscript.
Global Variable Names
The portion of the key corresponding to the name of the global variable holds an ASCII representation of the variable name excluding the caret symbol (^).
String Subscripts
YottaDB stores string subscripts as a variable length sequence of 8-bit codes ranging from 0 to 255. With UTF-8 specified at process startup, YottaDB stores string subscripts as a variable length sequence of 8-bit codes with UTF-8 encoding.
To distinguish strings from numerics while preserving collation sequence, YottaDB adds a byte containing hexadecimal FF to the front of all string subscripts. The interpreted form of the global variable ^A("Name",1)="Brad" looks like the following:
Block 3 Size 24 Level 0 TN 1 V7
Rec:1 Blk 3 Off 10 Size 14 Cmpc 0 Key ^A("Name",1)
10 : | 14 0 0 0 41 0 FF 4E 61 6D 65 0 BF 11 0 0 42 72 61 64|
| . . . . A . . N a m e . . . . . B r a d|
Note that hexadecimal FF is in front of the subscript "Name". YottaDB permits the use of the full range of legal characters in keys. Therefore, a null (ASCII 0) is an acceptable character in a string. YottaDB handles strings with embedded nulls by mapping 0x00 to 0x0101 and 0x01 to 0x0102. YottaDB treats 0x01 as an escape code. This resolves confusion when null is used in a key, and at the same time, maintains proper collating sequence. The following rules apply to character representation:
All codes except 00 and 01 represent the corresponding ASCII value.
00 is a terminator.
01 is an indicator to translate the next code using the following:
Code |
Means |
ASCII |
|---|---|---|
01 |
00 |
<NUL> |
02 |
01 |
<SOH> |
With UTF-8 character-set specified, the interpreted output displays a dot character for all graphic characters and malformed characters. For example, the internal representation of the global variable ^DS=$CHAR($$FUNC^%HD("0905"))_$ZCHAR(192) looks like the following:
Rec:1 Blk 3 Off 10 Size C Cmpc 0 Key ^DS
10 : | C 0 0 0 44 53 0 0 E0 A4 85 C0 |
| . . . . D S . . ? . |
Note that DSE displays the wellformed character ? for $CHAR($$FUNC^%HD("0905")) and a dot character for malformed character $ZCHAR(192).
With M character-set specified, the interpreted output displays a dot character for all non-ASCII characters and malformed characters.
Numeric Subscripts
Numeric Subscripts have the format:
[ sign bit ] [ biased exponent ] [ normalized mantissa ]
The sign bit and biased exponent together form the first byte of the numeric subscript. Bit seven (7) is the sign bit. Bits <6:0> comprise the exponent. The remaining bytes preceding the subscript terminator of one null (ASCII 0) byte represent the variable length mantissa. The following description shows a way of understanding how YottaDB converts each numeric subscript type to its internal format:
Zero (0) subscript (special case)
Represents zero as a single byte with the hexadecimal value 80 and requires no other conversion.
Mantissa
Normalizes by adjusting the exponent.
Creates packed-decimal representation.
If number has an odd number of digits, appends zero (0) to mantissa.
Adds one (1) to each byte in the mantissa.
Exponent
Stores exponent in first byte of subscript.
Biases exponent by adding hexadecimal 3F.
The resulting exponent falls in the hexadecimal range 3F to 7D if positive, and zero (0) to 3E if negative.
Sign
Sets exponent sign bit <7> in preparation for sign handling.
If the mantissa is negative: converts each byte of the subscript (including the exponent) to its one's-complement and appends a byte containing hexadecimal FF to the mantissa.
For example, the interpreted representation of the global ^NAME(.12,0,"STR",-34.56) looks like the following:
Rec:1 Blk 5 Off 10 Size 1A Cmpc 0 Key ^NAME(.12,0,"STR",-34.56)
10 : | 1A 0 0 61 4E 41 4D 45 0 BE 13 0 80 0 FF 53 54 52 0 3F|
| . . . a N A M E . . . . . . . S T R . ?|
24 : | CA A8 FF 0 0 31 |
| . . . . . 1 |
Note that CA A8 ones complement representation is 35 57 and then when you subtract one (1) from each byte in the mantissa you get 34 56.
Similarly, the interpreted representation of ^NAME(.12,0,"STR",-34.567) looks like the following:
Rec:1 Blk 5 Off 10 Size 1B Cmpc 0 Key ^NAME(.12,0,"STR",-34.567)
10 : | 1B 0 0 9 4E 41 4D 45 0 BE 13 0 80 0 FF 53 54 52 0 3F|
| . . . . N A M E . . . . . . . S T R . ?|
24 : | CA A8 8E FF 0 0 32 |
| . . . . . . 2 |
Note that since there is an odd number of digits, YottaDB appends zero (0) to the mantissa and one (1) to each byte in the mantissa.
